Structured Text: A cleaner way to deal with Rich Text in Manageable Content

A major feature everyone expects when it comes to manageable content, is the ability to author rich text content. At prismic.io we use what we call structured text chunks as a cleaner way for doing just that.
Historically a CMS was focused on website authoring, and considered as a tool for non technical people to "design a website". Therefore, most of CMSs have come to include a "WYSIWYG HTML editor" that allows content writers not only to enter some content, but also to visually design it.
A WYSIWYG editor might seem like a perfect tool at first, especially from the author point of view who gets the initial feeling that he will have the freedom to visually edit and change anything the way he want on its website. However any developer or designer, who once worked on integrating content managed using a WYSIWYG editor into a website or an application, knows that it is totally unmanageable.
As a developer, when querying data authered with a WYSIWYG editor, you end up with an opaque block of HTML, and you have no other choice but to throw it as is in the the page. This looks fine until you discover that this opaque block of HTML is overriding an otherwise coherent visual style carefully crafted by the designer. Even worse, it may totally break your page's layout.
Another problem with the WYSIWYG approach is that it becomes almost impossible to reuse the same chunk of content in different areas of the same website or across different websites. This also makes it a challenge to come up with a redesign of the website based on the same content, and do not even think about sending this content to a non-HTML-based viewer, like a mobile native application.
Of course, over the years, CMS developers have worked on some workarounds to relax some of these problems, like more complex editors that attempt to clean up the produced HTML. Nevertheless, when we started working on prismic.io, we knew that even if rich text fragments were crucial, the WYSIWYG HTML editor was certainly not the way to go. Instead, we chose the Structured Text path: providing a rich text editor that allows authors to express any logical text structures (emphasis, strong, link, image, ...), and to extract these as a meaningful data structure that we could provide through our Content Query API. This allows the developer to extract and display these content pieces as appropriate, with or without structure.
Authoring Structured Text fragments in a Writing Room
Just because the editor has to output a meaningful organized text structure doesn't mean it has to be cumbersome for content writers. Authors should enjoy a familiar editing process based on well-known patterns. Examples include creating a new text block using the Enter key, merging two text blocks using the Backspace key and many other obviously common text editing shortcuts despite the fact that the result is well structured. And when it comes to providing additional inline structure to the text such as identifying headings or important words, the author should find the familiar tool bar that you'd find on any rich text editor:
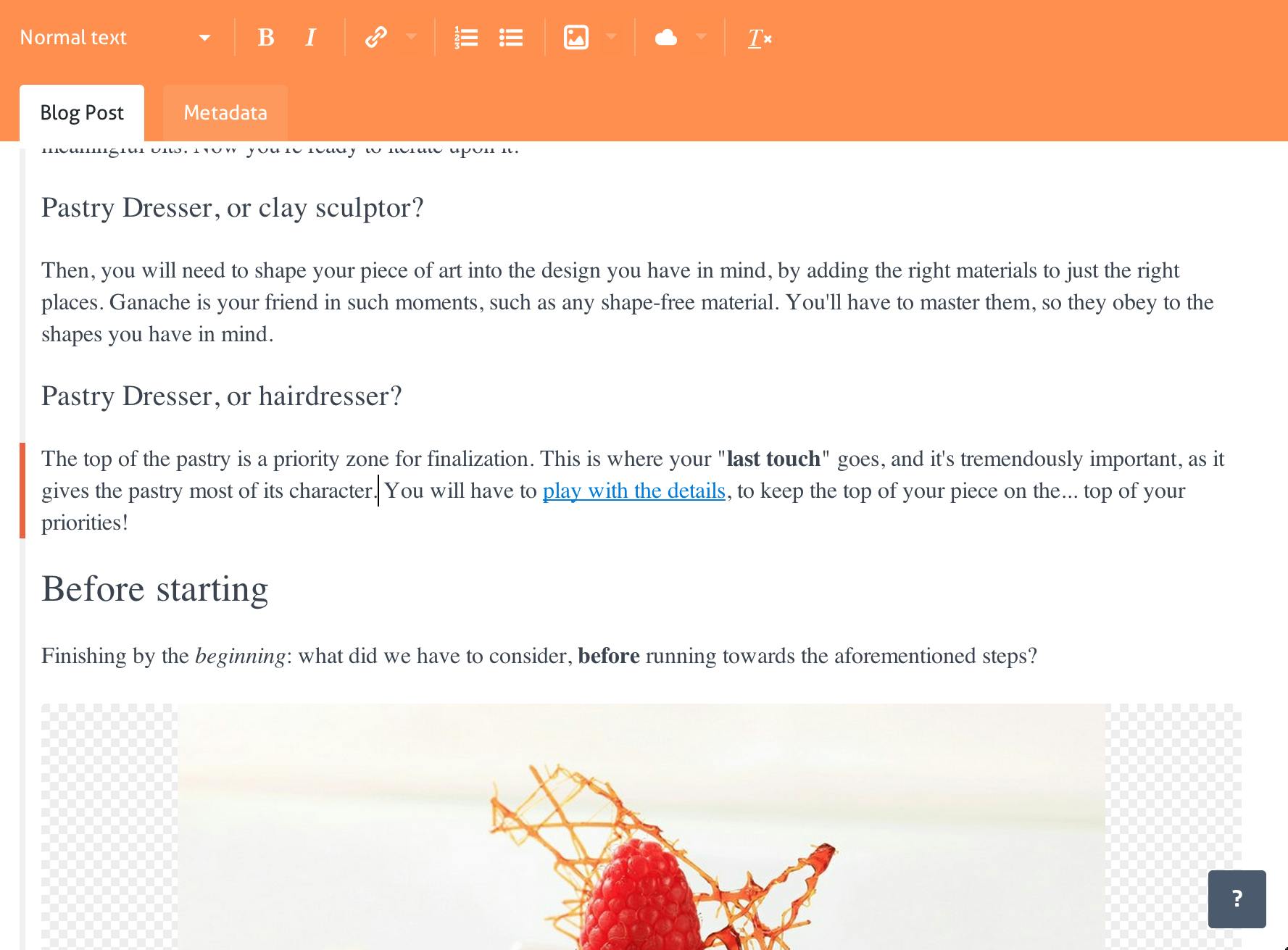
Under the hood we carefully track the author actions to transparently provide structure to the text fragment: as a result the author retains a familiar editing process without compromising the meaningfulness and the structure of authored text.
Tracking changes in Structured Text fragments
Another great benefit from maintaining a clean structured text appears when it comes to tracking changes. Computing and displaying differences between two rich text fragments is not an easy task, but thanks to the deep understanding of the text structure we have in prismic.io, it allows us to track changes in a very meaningful way.
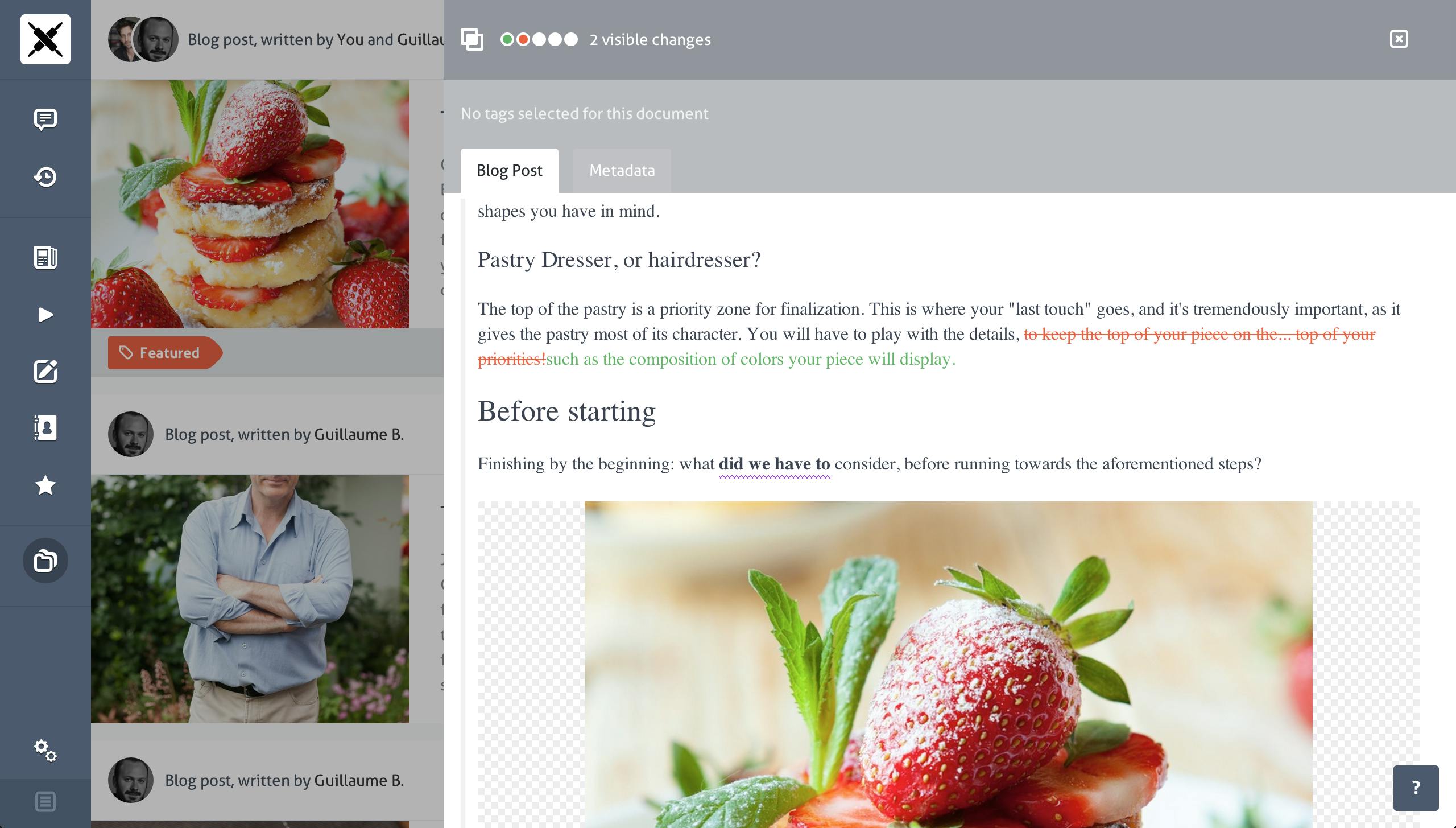
From prismic.io Structured Text content to your design
When you query a document containing some structured text chunks via the prismic.io content query API, you get access to the raw structured text data.
body: {
type: "StructuredText"
value: [
- { … }
- { … }
- { … }
- { … }
- { … }
- { … }
- { … }
- { … }
- { … }
- { … }
- { … }
- {
type: "paragraph"
text: "The top of the pastry is a priority zone for finalization. This is where your "last touch" goes, and it's tremendously important, as it gives the pastry most of its character. We didn't mention color, but it's a very important component of the piece. Just like an illustrator will pick colors that add to the shape in a matching way to keep a perfect meaning, the colors must be perfect to be consistent with the taste of the piece."
spans: [
- {
start: 78
end: 90
type: "strong"
}
- {
start: 175
end: 175
type: "hyperlink"
data: {
type: "Link.document"
value: {
document: {
id: "UlXJfLO534MB8xmZ"
type: "article"
tags: [ ]
slug: "dont-be-a-stranger"
}
isBroken: false
}
}
}
]
}
- {
type: "heading2"
text: "Before starting"
spans: [ ]
}
- {
type: "paragraph"
text: "Finishing by the beginning: what did we have to consider, before running towards the aforementioned steps?"
spans: [
- {
start: 28
end: 56
type: "strong"
}
]
}
- { … }
- { … }
- { … }
- { … }
- { … }
]
}The data is presented as an array, in which each element is a text block. For each text block you get the raw text string, a block type, and meta information about describing the text part. As a developer you can use all or only some of the available data. For example you can choose to display the raw text (ignoring any formatting information), apply some structure, pick up just the first heading or paragraph, or any other appropriate manipulation.
Of course it is a very common task to translate these raw structured text data into either plain text or HTML. This is why, in prismic.io, any of our development kit provides out of the box helpers for these tasks. For example, using the JavaScript development kit, you can easily request the HTML view for any StructuredText fragment:
var htmlString = doc.getStructuredText('product.description').asHtml();Or the same, just as plain text:
var plainText = doc.getText('product.description');Since the text is carrying all the structure information, you can also explore the data further. Let's say that you want to dynamically extract some meaningful parts of a blog post in order to present it on the home page. You could want to get a title, the first 100 words and an illustration if possible:
var body = doc.getStructuredText('blog.body');
var preview = {
title: body.getTile() || null,
excerpt: _.take(body.getFirstParagraph().text.split(' '), 100).join(' '),
maybeImage: body.getFirstImage() ? body.getFirstImage().url : null
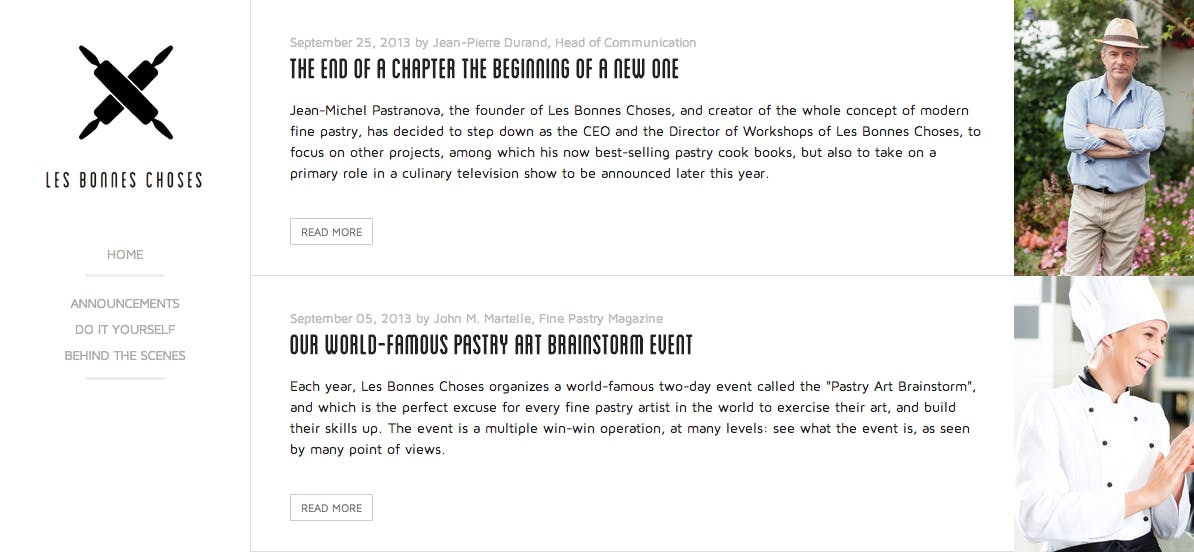
};If you take a look at our "Les Bonnes Choses" example, you can see how we use this technique to present the blog posts on the blog's front page.
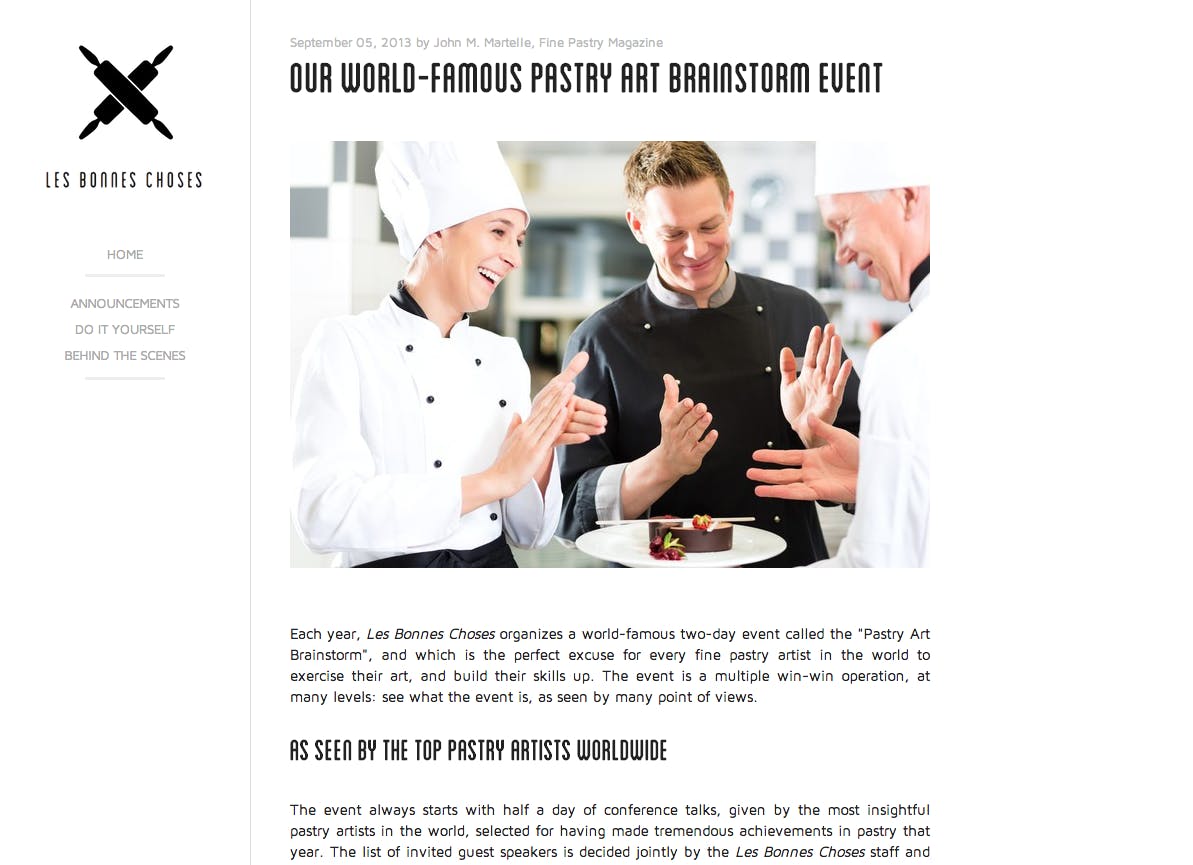
While, the same content is displayed with the complete original formatting on any detail page ( note the text formatting in paragraphs):
You can retrieve the code behind "Les Bonnes Choses" in different technologies on our GitHub page.
Querying a Structured Text
Having a proper data structure for rich text elements also help to query over your document set. Our Content Query API being based on a predicate-based query language, it makes it possible to offer many ways to select documents based on a deep analysis of some structured text chunks, such as selecting all blog posts that contain at least one image of the specified size.
Also one of the most common query you probably want to make, is doing for a full-text seearch, such as finding all blog posts that talk about "chocolate". As you'd expect, the search will take into account the text structure for emphasizing important parts of the text. You can express a full-text search very easily over our API using a predicate:
[:d = fulltext(my.blog-post.body, "chocolate")]Structured Text, multi-medium friendly and future proof
As a result, altough easily authored by a content writer using a familar editor and tools, we make no compromise with the quality of the content presented over our Content Query API. Your content is probably here to stay a long time, and it is important that you make sure that you will be able to exploit it the way you want, to display it onto as many mediums as you need, and to adapt it to the next design trend when it will be time to refactor your website(s) or app(s) design.