Last week, we successfully launched prismic.io, introducing several new concepts into the cluttered Content Management world (and breaking a bunch of assumptions about how to manage content). In the last few days since then, we've received loads of positive feedback, we're glad lots of hackers have a good grasp of the concepts. We've also been receiving plenty of very interesting questions.
One of the questions we've been asked quite frequently so far is: how do we ensure prismic.io API's high availability and scalability. This question is vital for an API that is serving something as central as content to an app or a website. One of the important goals of prismic.io's API is to make it easier for your app or website to perform well and scale with your project success. This blog post aims at gently introducing you to some aspects of prismic.io API's architecture, and to emphasize on how some simple architectural decisions can guarantee high availability and elastic scalability of our API.
To dive into these details, we need first to introduce in more depth a very central feature to prismic.io: releases.
Releases
Content in prismic.io is organized in documents, and a document contains fragments of different types of content primitives. Instances of a document can vary from an implicitly structured blog article (like this very one), to a very thoroughly structured product (as in our sample website example)
In prismic.io, documents are immutable. This simply means that anytime you modify a document, we create a new version of it. This is what allows you to experiment with your content without being worried about losing changes. For example, while experimenting with descriptions of the Soft Lemon Cupcake, different versions of that document will exist.
A release refers to a coherent set of document versions. For example the Live release refers to all document versions that are live at the moment. Another example: Les Bonnes Choses includes a non-yet-published release called "Announcement of new SF shop" which adds a new store document, a new blog post document for the announcement, and makes changes in a few articles in the website to mention and link to the new opening SF store!
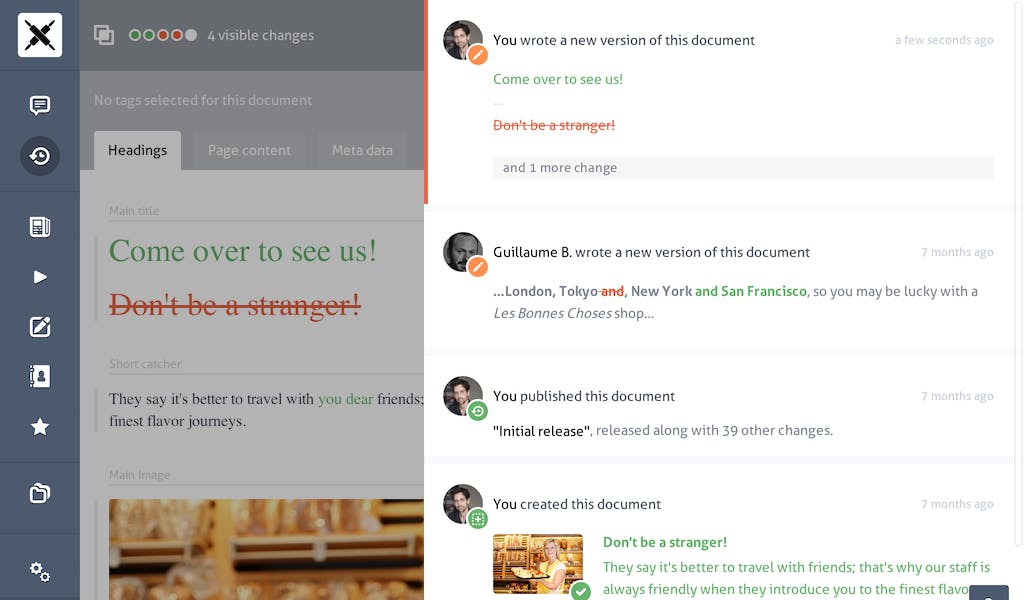
As you can see, releases are instrumental for organizing content modification into coherent projects. They also allow you to preview changes the way they will happen, and then schedule publishing them all together at once.
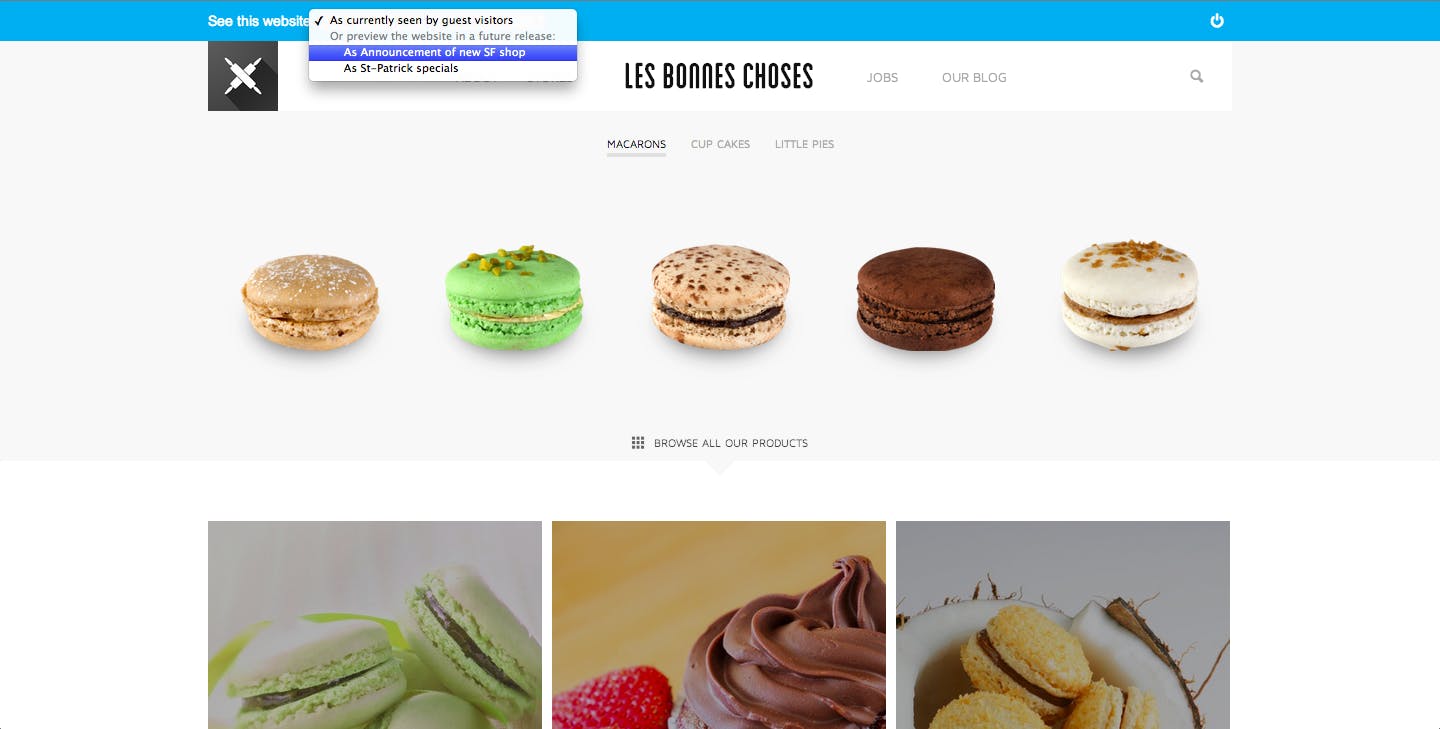
Scaling a release-oriented API
prismic.io's API is organized around releases. Anytime you need to perform a query or a search, you need to specify first on which release you will be working. This is what allows you to preview a set of changes to your content before they are actually published.
To understand better how can we guarantee uptime and scalabilty of our API, we need to have a look at how releases are actually represented:
A release as an index
Whenever you create or update a release, we create a new index representing all possible searches on that release, together with contents of returned documents. This means that whenever a change is pushed into a release, we scan all documents referenced by the release, we index them and package them with the index in a standalone Lucene index. Lucene is the most popular indexing and search technology developed on top of different platforms.
The fact the index is standalone is crucial here. It really means that to serve API queries for that release, all that we need is the packaged index! In other words, on a blank server, all we need is to have the index around, and we're up!
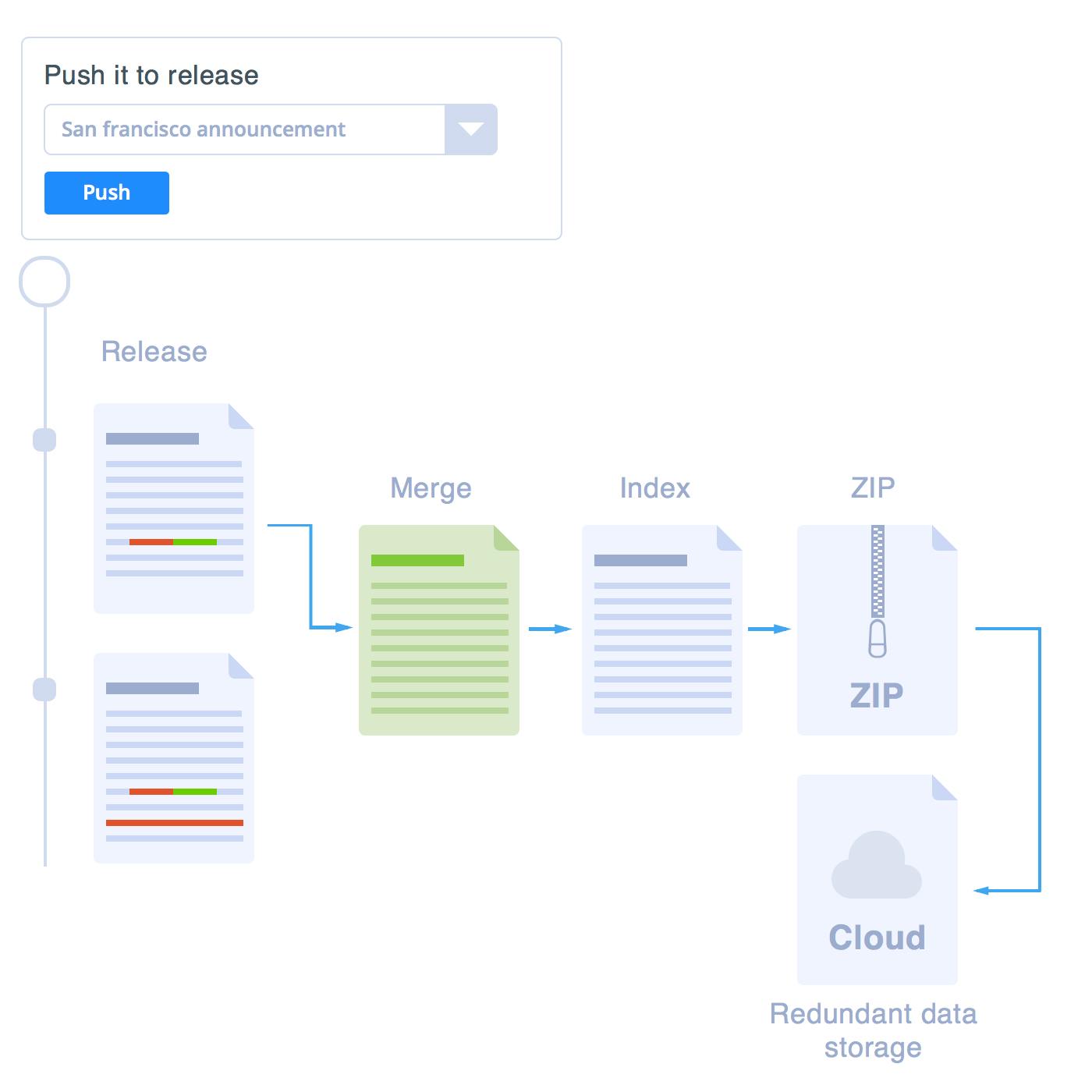
Backing up indexes
To take full advantage of the standalone property of a release API, anytime a Lucene index is produced, we package it and back it up on a redundant distributed storage server. We have our servers look for indexes in that storage, download them and start serving them: as simply as it sounds. This simply means infinite and elastic scalability. A server only needs to have an operating system running, Java Virtual Machine installed, and our app. Whenever a user hits that blank machine querying on a release, it will download the release's packaged index and start serving it.
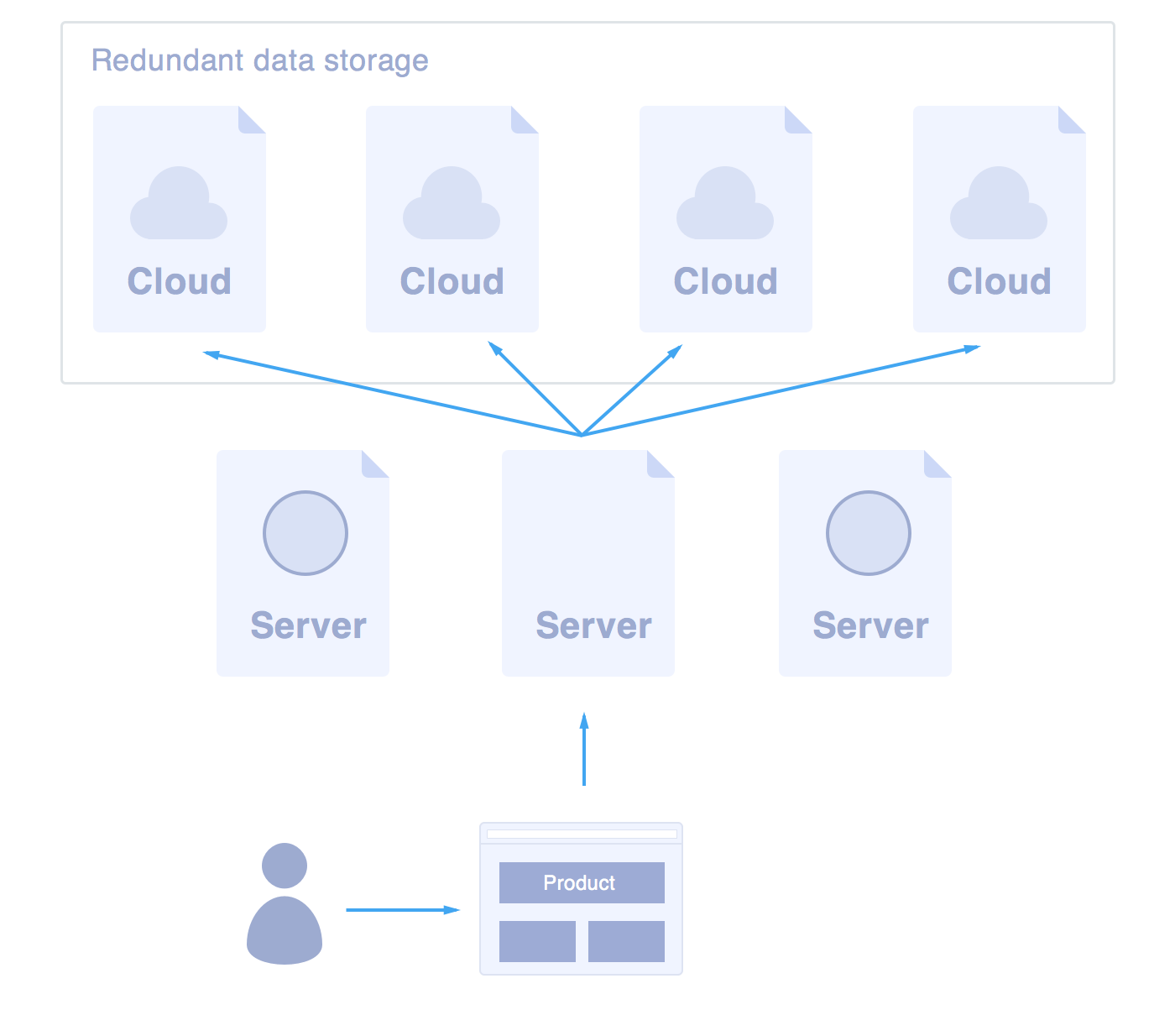
This also means that we've detached our API from our content management constraints, API performance won't be affected by any database technology load and performance. The result is such that, even if for any reason we had to bring down prismic.io for maintainance, the API will still be up. This also allows us to guarantee a high availability - because we're being extremely reactive in disaster situations (like a datacenter going down), deploying the API is a piece of cake!
Building a release index
A question might arise from this architecture explanation: how expensive is it to build the Lucene index each time a modification is pushed to a release? It is reasonable to ask how so much indexing and packaging work couldn't affect your editing and publishing workflow in prismic.io - especially when a large number of documents and changes is involved.
The answer is quite simple: a release always builds on top of another, earlier release. Actually, a release only mentions documents that have been changed since the preceding release. Taking this into account, we do not build indexes from scratch, but rather build on top of the existing release, modifying only indexes of documents that have been changed.
And more
In a future article we will see how can we use this kind of architecture to optimize our caching without giving up instataneous delivery of changes. Caching allows your app or website to save unnecessary requests by reusing answers to previously used queries.
Stay tuned!