Building a GEO Benchmark Tool: What We Learned Polling LLMs at Scale


LLMs are becoming a discovery channel. Questions like "What CMS should I use for a Nuxt site?" are now increasingly asked to ChatGPT, not Google. This shift matters: if AI assistants are shaping what tools people consider, we want to understand how Prismic shows up in those conversations. And ideally, measure it.
So we built a tool for that. It came out of our Agent Lab, a quarter where our marketing team experimented with building AI agents. On my end, I took that as an opportunity to try an idea I’ve had for a while: could we "benchmark" LLMs the way people benchmark performance, but for brand visibility instead? What I didn't expect was that my curiosity project would turn into one of our internal tools, serving both our sales and marketing playbooks.
So, how do you actually benchmark language models for something like this?
Polling LLMs like you’re running a survey
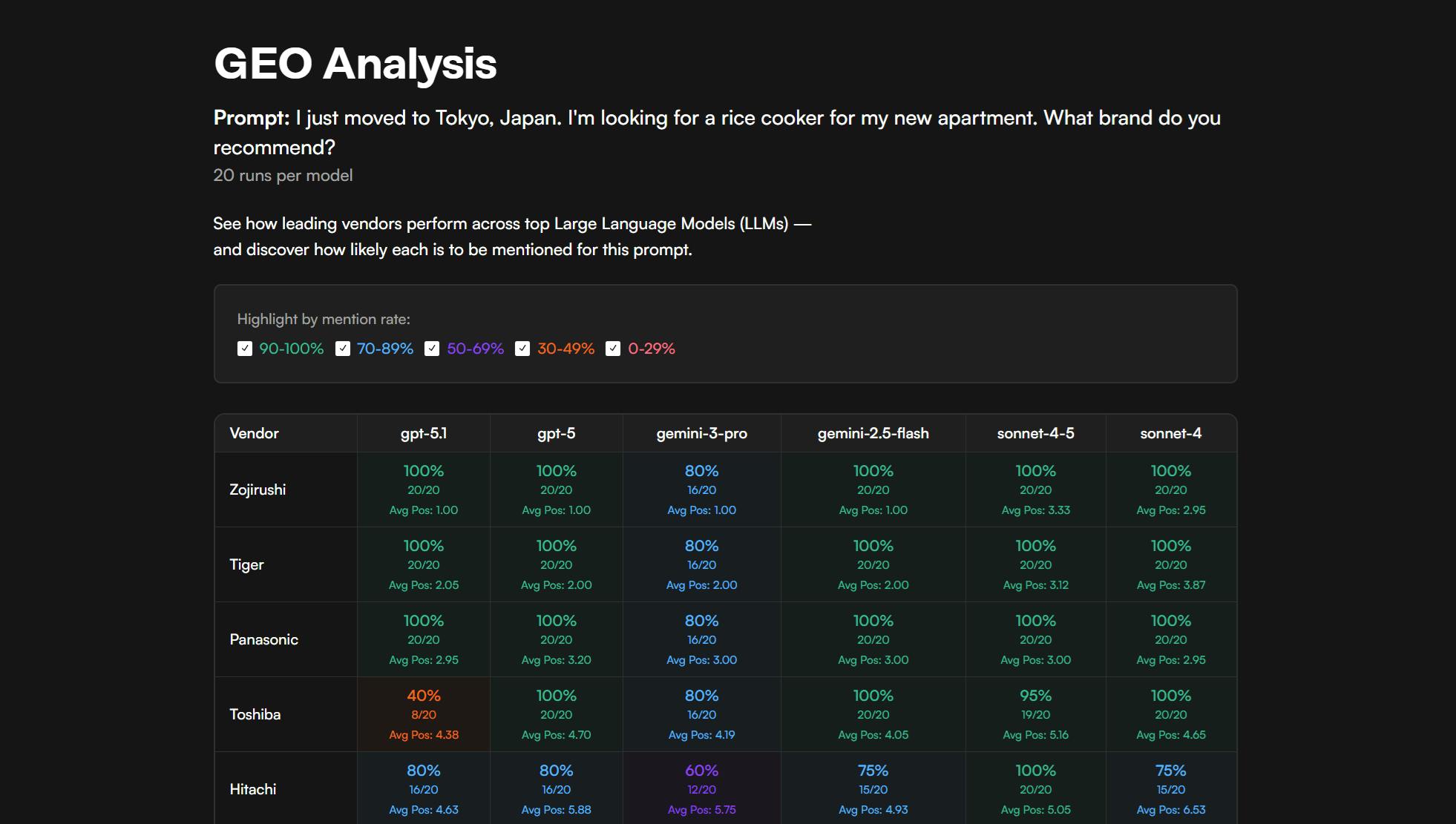
The core idea is simple: ask the same prompt to multiple models many times and aggregate the results. It's like running a poll, except instead of asking different people every time, you keep asking GPT-5, Claude, and Gemini what they'd recommend. Do that enough times, and you start seeing patterns.
But why run the same prompt multiple times? If you ask ChatGPT "what CMS should I use?" twice, you’ll very likely get two different answers: the model might search different sources, weigh factors differently, or just land on a different phrasing. A single query tells you what the model said once; running 20 iterations per model per prompt gives you a statistical picture, and all of a sudden, you start seeing which vendors get mentioned consistently versus which ones appear sporadically.
Now, if you're going to poll multiple providers with the same prompt, you need a way to communicate with all of them consistently, ideally with minimal overhead. That's exactly what Vercel's AI SDK is designed for.
Using the AI SDK
The AI SDK is a developer toolkit that provides a unified interface to call models from OpenAI, Anthropic, Google, and others through code. Instead of learning three different APIs with three different response shapes, you write one integration and swap providers as needed. For our use case, running identical prompts across providers and comparing apples to apples, this was ideal.
That said, the AI SDK abstracts a lot, but not everything. Provider-specific quirks remain, and we encountered a few of them. One example:
We wanted to track what sources LLMs consult when answering prompts. When a model searches the web to answer your question, what queries does it run? What pages does it end up citing? This data would help us understand not just what models recommend, but why. On one hand, OpenAI reports this information fully: you get the search queries, the sources, everything. On the other hand, Google Gemini only reports partial data, and for Anthropic, we ran into issues getting their search tool to work reliably.
The lesson here isn't that AI SDK is bad; it's genuinely great for what it does, and our use case is admittedly a bit exotic. But if you're building something similar, expect to handle small provider differences case by case.
First time here? Discover what Prismic can do!
👋 Meet Prismic, your solution for creating performant websites! Developers, build with your preferred tech stack and deliver a visual page builder to marketers so they can quickly create on-brand pages independently!

The accuracy problem of structured output
With the infrastructure sorted, the next question was what to do with the responses. Our first instinct was to use a structured output: asking the model to respond in a specific format, such as JSON, rather than natural prose. Instead of "I'd recommend checking out Prismic or Contentful for your use case because..." you get:
{
"recommendations": [
{ "name": "Prismic", "rank": 1 },
{ "name": "Contentful", "rank": 2 }
]
}From a developer's perspective, this is perfect. Structured output is easy to parse and cheap to process. No messy text extraction, no ambiguity about what counts as a "mention." Just clean data.
The problem? This isn't how real users prompt ChatGPT. Nobody types "return JSON with your top 5 CMS recommendations ranked by suitability for a marketing website." They type "I'm building a Next.js site for my marketing team, what CMS should I use?" and get a conversational response.
When we compared our structured output results against manual sampling (i.e. actually going into ChatGPT and Claude and running prompts as a normal person would), the numbers didn't match. Indeed, asking models to rank things in a list produces different results than letting them reason naturally: the structured format itself was skewing our data.
So we changed our approach: prompt naturally, then extract vendor mentions from the prose response. It's more work on the parsing side, for sure, but the results are closer to what users actually experience. And that's the whole point: we're trying to understand how Prismic shows up when real people ask real questions, not how it performs in a synthetic benchmark.
From Slack toy to sales tool
With the polling agent built, we set it up to run weekly benchmarks on a set of CMS-related prompts and report the results to Slack. This gave us a baseline: we could track our ranking over time and test whether specific initiatives had any measurable impact on how LLMs talked about us. But the real unlock came when our sales team got involved.
"Can we run this for prospects before calls?"
Now the tool is integrated into our Clay workflows: take a prospect list, auto-generate prompts based on their industries, run benchmarks showing how their brands rank against competitors, and push the report URLs to HubSpot. Before a call, sales can hand prospects a snapshot of their current GEO standing: where they show up, where they don't, and how they compare. It's a conversation starter that demonstrates we understand this space, and naturally leads into how our GEO features can help them improve those numbers.
The economics: tokens ain’t free
When it comes to numbers, the cost of running our benchmark tool also helps explain the AEO/GEO landscape.
Each benchmark we run costs us roughly $0.50~1.00 for 120 prompts across models. That's reasonable for on-demand snapshots. Even if we run a few per day to support sales calls, the total cost lands around $50~100 per month, comfortably within our Customer Acquisition Cost.
Now, let’s think about what dedicated GEO tools like Profound, Otterly, or Peec offer: daily tracking, across hundreds of prompts, with historical baselines and trend analysis. At our per-benchmark cost, daily tracking for even a modest set of prompts would run into hundreds of dollars monthly. Weekly tracking across a broad prompt set? You're easily looking at the pricing tiers these tools actually charge.
Either way, comprehensive, ongoing GEO monitoring is expensive to run, and there's a tradeoff worth understanding: the further you optimize away from "what a real ChatGPT session looks like" (limiting thinking, using simplified prompts, skipping web search), the cheaper, but also the less accurate the results get.
Similar, but serving different goals
I'm a hobbyist photographer, so here's a camera metaphor: our tool is short exposure, single frame. It's great for a quick snapshot of where you stand on a specific prompt, right now. Need to know how that prospect ranks in their industry before a sales call tomorrow? We can tell you in minutes.
Dedicated platforms like Profound are long exposure, or more like movies. They track drift over time, show sector-wide trends, and build historical baselines you can analyze over months. We now use them at Prismic too, but only to track our own ranking. If you also need that sustained visibility into how your brand appears across AI assistants, use them! They're built for it.
Different jobs, different tools. Ours went from a personal experiment to something used across the company in a matter of weeks, and it's working well for what we need. That's something I love about having space to experiment: sometimes the side project becomes the main project, and this is one of them.